How We Reduced our Google Cloud Bills by 50 Percent

In 2019, we launched Lykdat.com, a Shazam for Fashion solution that enabled shoppers find where they can buy products by searching with images.
If you’re thinking computer vision, then you’re absolutely right. But if you’re also thinking web crawling and scrapers, you'd also be right.
Being able to recommend internet products via image search meant that all fashion products on the internet needed to exist in in our Database. We also needed to constantly update them.
When we launched in 2019, we started with a few online stores as Proof of Concept and had copies of only about 600k products in our DB.
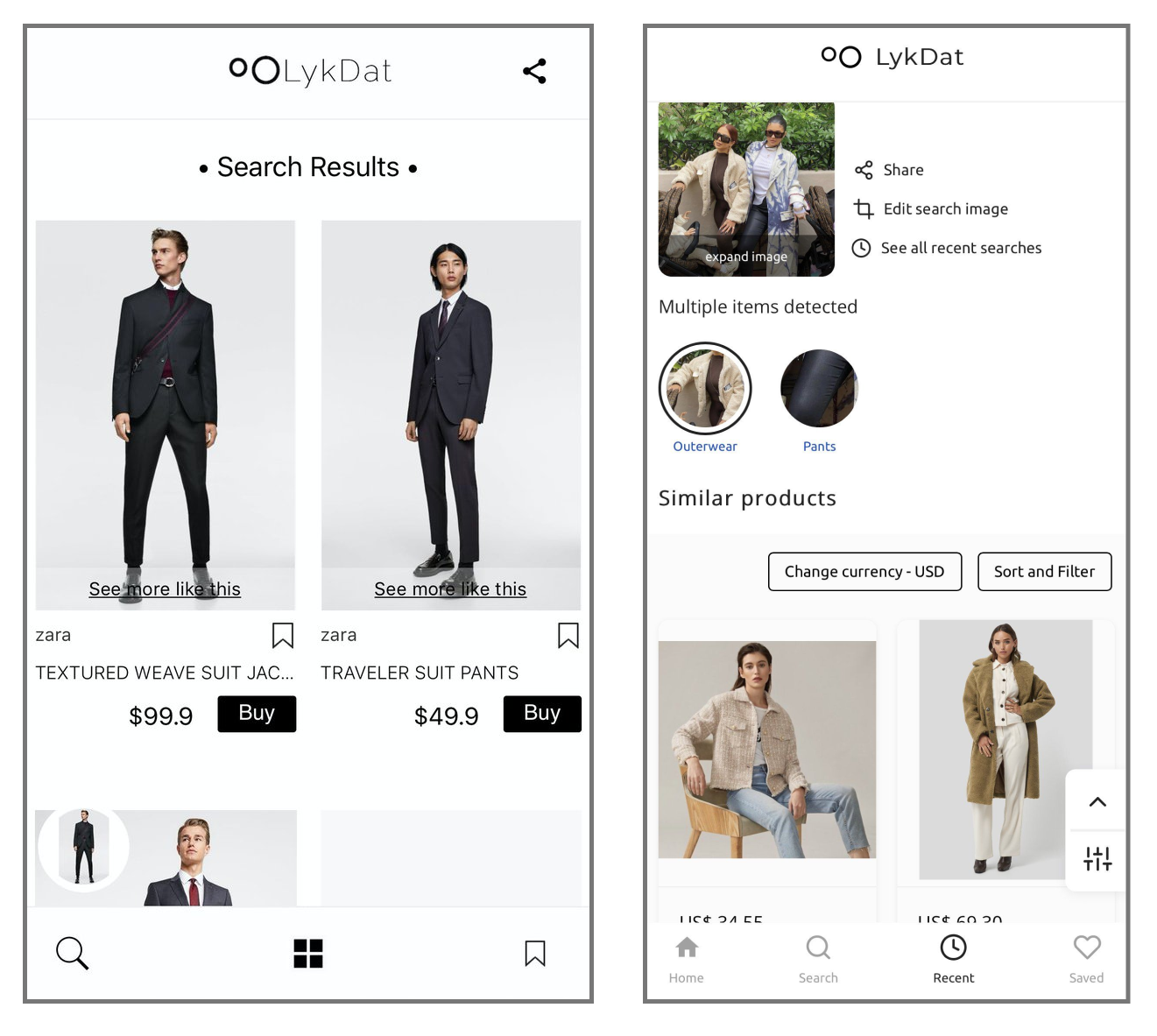
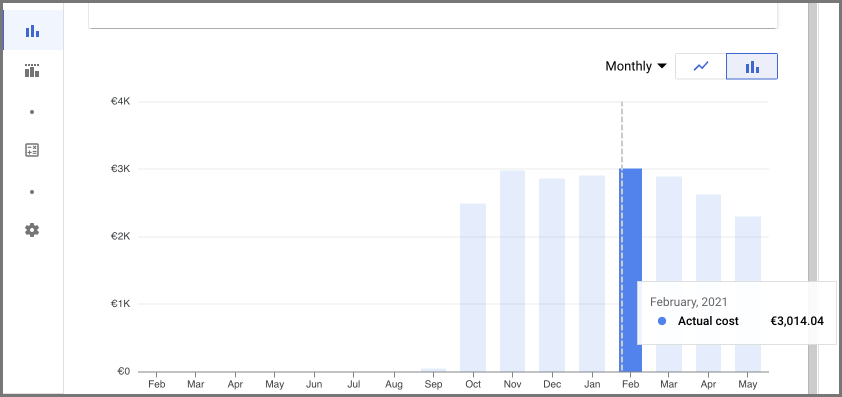
By 2021, we had grown to crawling over 200 online stores and had a Database of over 11 million products with our Google Cloud bill running up to over 3k EUR monthly.
We had gained some traction, with about 45k users monthly, and with search result accuracy at about 60%. Meaning for every 10 searches done on our site, about 6 of them found the exact product the user searched for. The remaining 4 searches found similar items, but not the exact item.
With those similar items also came DUPLICATES. 🤧
Almost every time you did a search, you will find that some products in the results would appear multiple times. These were duplicate products that existed in our Database.
Bear in mind, each product in the Database had a unique ID, and so did these duplicate products. However, visibly, they were duplicates, and this was the case for the following reasons:
- For some, it was a case of the same apparel item, but in various sizes (e.g L, XL, M). So they had the same images, name, and url but different ID due to size.
- For some others, it was a case of the same apparel item but sold by different websites/vendors.
- For some, it was a case of the same item but in different languages. So imagine ASOS UK and ASOS Spain. The same apparel items, same images, but different URLs, and different names (one in English and other in Spanish).
- For others, I can’t remember what they were unfortunately, but I’m sure there were other cases.
At the time, we had no easy way of measuring what fraction of our entire catalog were duplicates. It would require writing some kind of script to run through our entire Database, but that was really not top priority, so our first way of resolving this was resorting to a Frontend hack. Our major concern was “hey, some users will see the same product appear 4-5 times, and that’s not a good look”. So what we did on the Frontend was to hide duplicates in the search result by comparing product name, price and vendor.

That seemed to reduce the rate at which duplicates appeared on the result page. But we’d still find some duplicates slip through the cracks now and then, and of course, they still existed in our Database.
Our Database kept growing, and so did our cloud infra bills. We were running our scrapers every week, adding new products, and updating old products. Our bills were climbing and approaching 4K EUR monthly, and it was killing us. We are a self-funded company and clearly couldn’t afford it any longer.
It was time for us to do something about it, and it had now become top priority. It was either that, or the company won’t stay alive for much longer.
What We Did
We started out with the low-hanging fruits, which were for example, duplicates that existed in Product URLs, Product IDs, etc.
Product URLs
We indexed the Product URL field, and did a DB scan for product URLs that occurred more than once.
Basically if a product URL had more than one occurrence in the DB, we will delete other occurrences and keep only one.
The Hoops that came with Product URLs
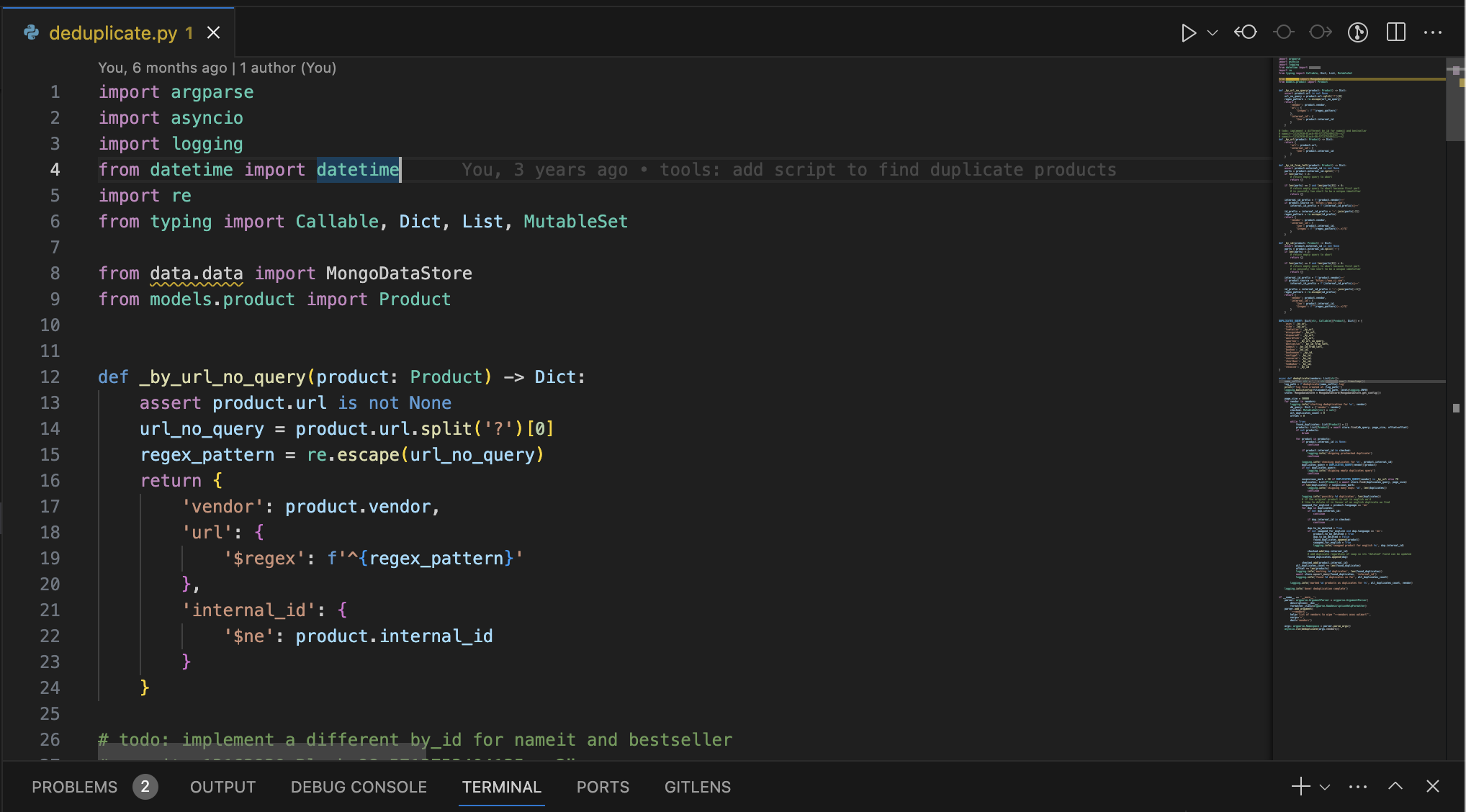
When we tried using product URLs to detect duplicates, there were cases where the URLs were slightly different based on query parameters. So we had a special case for those where we’d match the prefixing URL and exclude the query.
Similar Product IDs
The next low-hanging fruit was the case where Product IDs were similar. For example, if products duplicates existed because they were different sizes, the IDs were merely different by suffixes. So Product A could have ID B2894NSLKA-XL whereas Product B will have ID B2894NSLKA-L. Where -XL and -L represented the sizes. We wrote a script to do a DB scan that would essentially do a regex match of the ID prefix. These DB scans were not slow because the product ID field was indexed and we were matching the prefix (which is an important bit with the case of indexes) and we scanned only for a set of online stores.
The Not So Low-hanging Fruit

Now for the tricky part — which is for the case where the images were simply the same, and nothing else gave it away but the images.
What We Did
The first step was to generate the MD5 hash for each product’s image and store it as an indexed field in DB. This was easy to add to our process because MD5 was already being generated to validate image uploads, we just now needed to save them in the DB as well.
Doing this would help us identify duplicate images in the DB when they have the same MD5 hashes.
The Hoops that came with MD5
- MD5 conflicts are unlikely, but possible. Meaning 2 or more nonidentical images may have the same MD5 hash.
- Different products may have the same image but sell different Items. For example if the image contains a model wearing pants and a shirt. The first product with the image may actually be for the pants, and the second product with the same image may be for the shirt.
We addressed these hoops by scanning the DB for duplicate MD5 hashes, but for every duplicate hash, we will validate that they came from the same online store and they had the same Product name. If one was in English and the other was in a non-English language, we’d discard the non-English item.
More Hoops
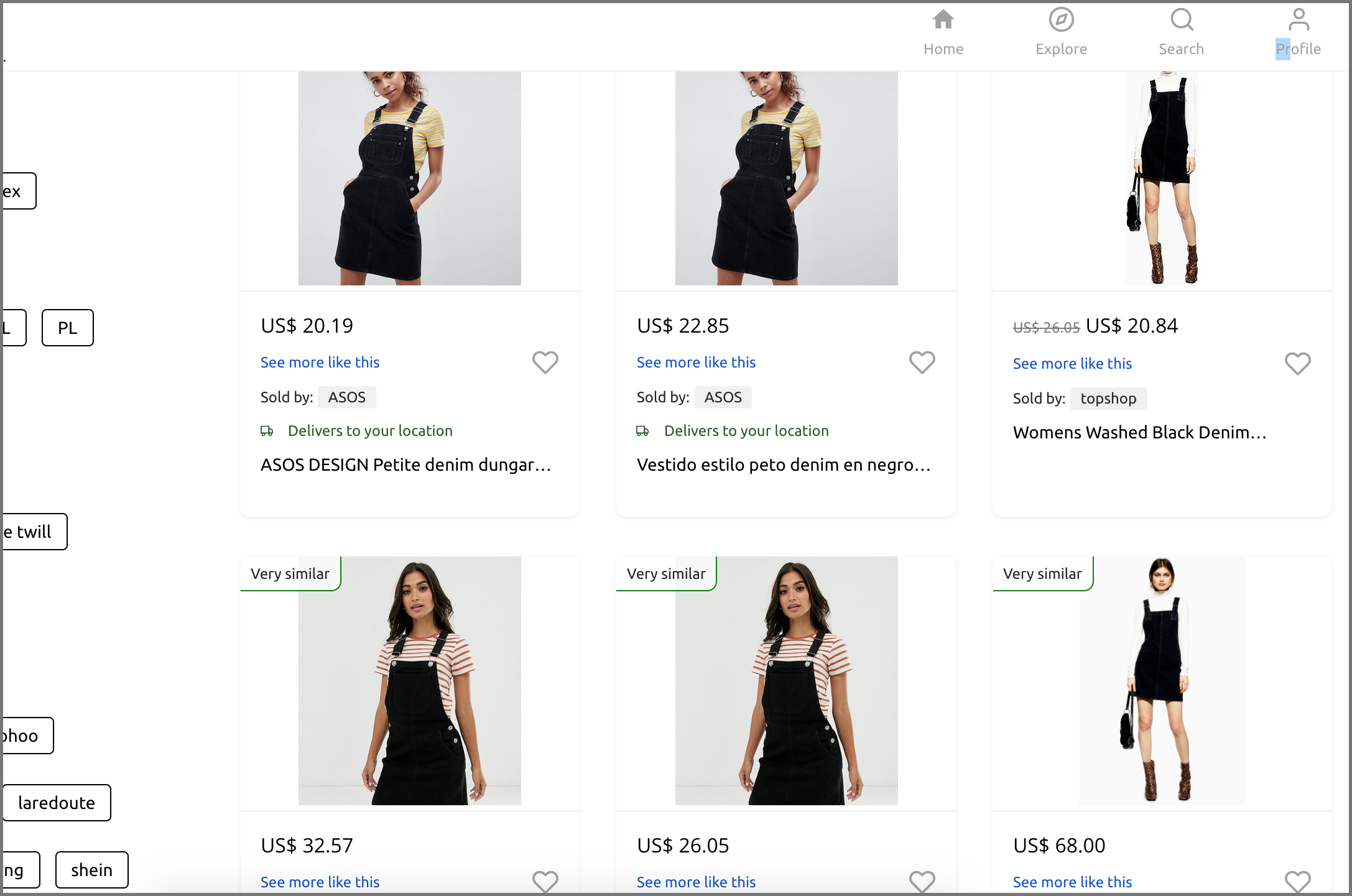
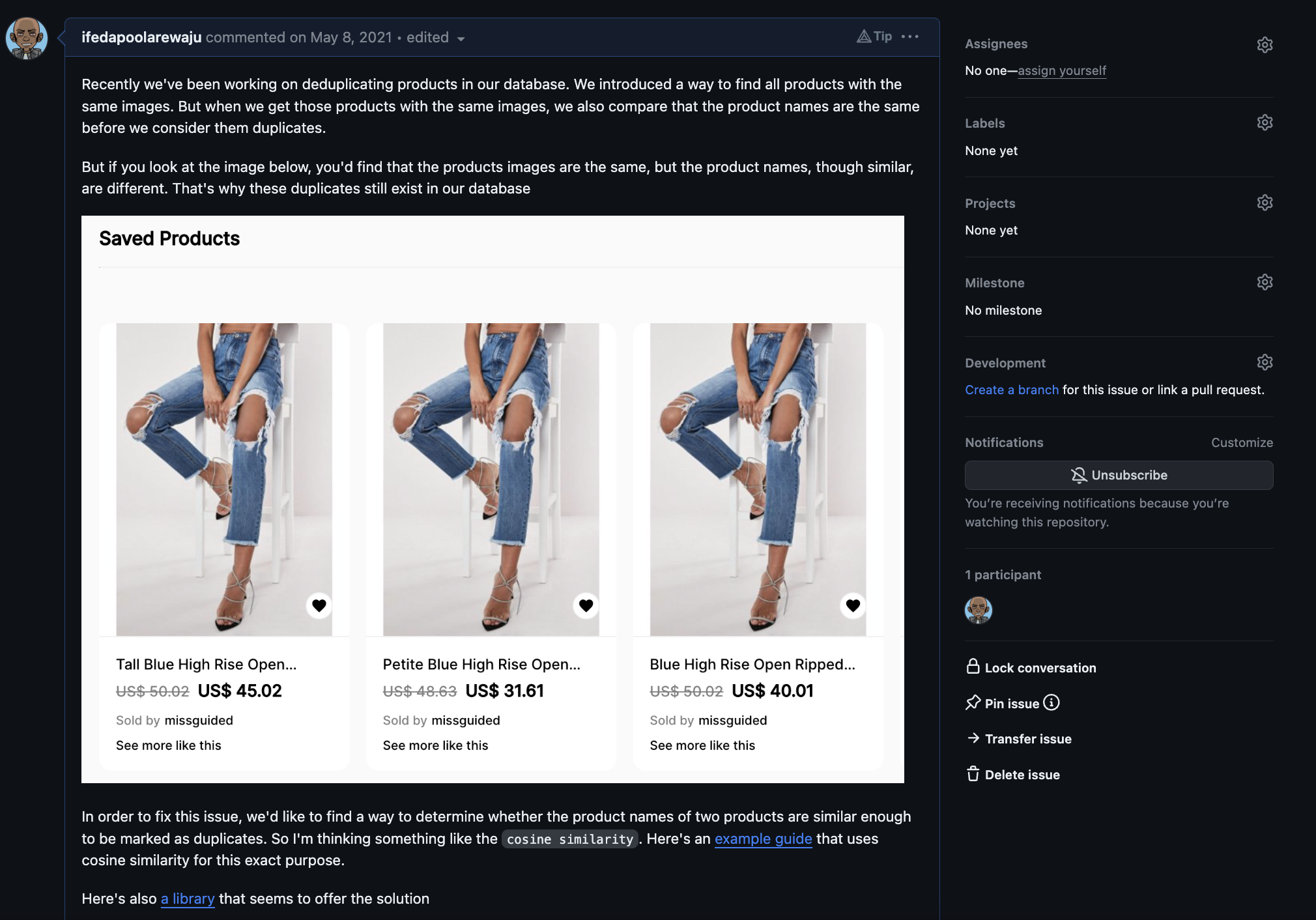
After running the script, there was still a significant number of MD5 duplicates that didn't get deleted from our DB (yikes! 😕). This was because, for many cases, the product names were slightly different.
Have a look at the screenshot below where I describe the issue. The products are same, with the same image, however, the products have slightly different names.
We addressed this by calculating the text similarity using the Cosine similarity method. Thanks to Open Source, we didn't have to implement the Cosine Similarity method from scratch.
So we modified the script in the previous section to:
- Scan the DB for duplicate MD5 hashes ...
- For every duplicate, we validate that they come from the same vendor and that their names are similar by over 80% (using Cosine similarity).
By the time we ran this script along with the previous scripts, we had ended up deleting nearly half the products in our Database. Earlier on when we wondered what fraction of our catalog the duplicates occupied, we most definitely wouldn’t have thought it was damn near 50%.
This endeavour helped us reduce our cost tremendously (by nearly 50%), and is one of the efforts that has kept us alive as a company.
Thank you for taking the time to read this article. I appreciate your curiosity and hope you enjoyed our survival story. 🤭